The Road to the Tildes 2020 Census: Pandemic Boogaloo
Hello everyone!
Some of you may remember last years census. I did say I wanted to repeat it, and have decided to push the date forward, as last year a few people said that doing it in December at the end of the year probably wasn't the smartest choice, due to well, christmas and new year's eve and I totally agree. Wish I would've seen that earlier, but I guess I'm dumb lol. Summer may give us better stats because more people are on vacation any maybe check in more regularily. Or maybe there's also less people around because everyone's on vacation. Who fucking knows, I don't know. I don't know anything.
Anyway, just like last time, I'd like to organize a preliminary discussion about the census and what questions we should ask this community. As a reminder, this was the 2019 census.
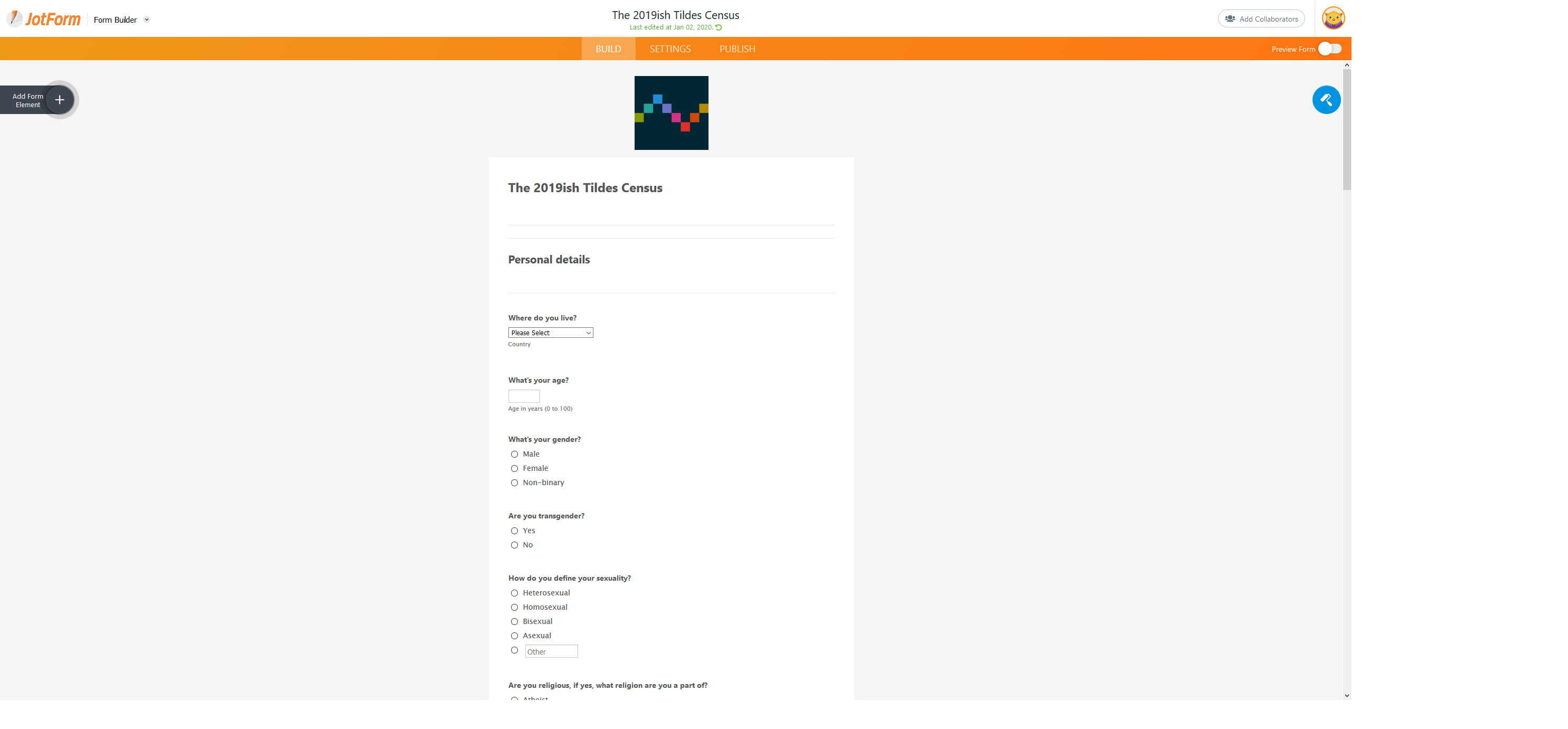{kind=link}
Areas that I'd like to improve: Politics, mainly. The 8values test I think is good, but maybe there's something better out there. We could do it with the political compass and go full quadrant and r/politicalcompassmemes, but of course that's also not going to be very accurate. I honestly don't even know if there's a good solution to this problem.
Other than that, are there other questions you'd like to ask the community? Let's discuss!I hope someone replies or this is gonna be emberassing.
This was already on last years census. However I just realized that the screenshot I posted was incomplete. Thanks Firefox screenshot capture function, I trusted you.
I agree, and the fields have been converted to checkboxes (was already like this for computers, but the mobile devices were still single choice).
I remember having this discussion last year, I think you came late to the party and the census was already ongoing, so I felt uncomfortable releasing the data, as I had stated earlier that I wouldn't. We have plenty of people on Tildes who care a lot about their privacy, and I remember at least one person who didn't answer specifically because they thought the personal detail fields were mandatory. I personally don't have a problem with releasing the census data, but if people don't want their aggregated data to be released to the public, I can't do anything about that. Of course with the data being public, we'd get a diverse analysis from different points of view, but otherwise my analysis is better than none, I guess.
One idea would be to release the data encrypted, and send out the password via Tildes DMs to those who would like to analyse the data. Not very secure of course, but it would be better than just releasing the CSVs to the public.
That choice didn't exist. If you answered the census, your answers were part of the data. However none of the fields were mandatory to fill out, so therefore you had the choice what data to give.
I'd encourage you and actually everyone to consider how even a few specific details in conjunction can deanonymize someone. Because our userbase is relatively small, it takes only a few pieces of data to narrow down an entry to a high level of confidence, particularly if one or more of them is uncommon.
An entry identifying a male, gay, Linux user who works in education doesn't point directly to me, for example, but it does reduce the possible pool for that entry significantly, where it likely only applies to a maximum of maybe 10 people here (I'd be surprised if it were that high, to be honest). Add to that other information (age range, location, education, etc.) that people either know or can infer about me, and they could easily find my specific entry without any direct links to my username.
I did not realize that's what you were advocating for! Thanks for clarifying. I support this.
I agree with you and kfwyre that this is much better from a privacy standpoint. The trade off is that it is much less useful from an analysis standpoint, as you can't really correlate anything.
But, it's still interesting, and I think this is a fine choice for a somewhat informal census.
I'm not one of the people likely to do analysis, so I don't actually know how they would feel about this method of releasing the data
I think this is a good idea, and tbh it's kind of what I did last year anyway, just not in a machine-readable format. I don't think anyone would have a problem with this.
I agree this would be a better way to disclose the raw data.
This is a very real concern. kfwyre is not the only person who would be so identifiable, it is surprisingly easy to do for most people if you have the will-power, some basic information, and some basic statistics.
My understanding is that the current state-of-the-art for dataset anonymization is differential privacy1. This may be much too complicated for Grzmot to implement single-handedly (I don't know if there are any good libraries/programs that can do this automatically), but it would make it more tolerable to publicly release the data.
We could also look into k-anonymity, as that is easier to implement, but it still may not be sufficient for a survey with only 250 responses2.
1: The Wikipedia article is super math-y. For an explanation targeted to laypeople, check out the minutephysics video on it.
2: My source is last year's results.
You could provide an opt-out for just the raw data public release (no opt out from aggregated public release).
But then everyone elses graphs/data/analysis would be scuffed, as parts would be missing.
Yeah, it's a workaround. To be clear I'd be in favour of just having the data fully dumped in public, with a big disclaimer you'll be doing that as the first thing the user reads.
I don’t think that would be functionally different as people who care about that data being released will just self-select out of completing it at all. At least with a check box you can still get those people included in the aggregated statistics.
Perhaps we could just ask decently vague questions and have more specific answers be optional? @Algernon_Asimov was the one who noped out because he wanted an age range instead of an exact age so asking a few questions of varying specificity like so:
"What's your age?"
By decile (10-20 to 90-100)
By quintile (10-15 to 95-100)
By year (13/TOS/legal minimum to 100)
And make the top one obligatory and the other 2 optional (or including a "answered above" option) might be a solution, since it lets you pick how specific you're gonna be about yourself.
I think this can be applied to a decent amount of questions (i.e relationships can probably be simplified) but I'm not sure how many.
That's better, but if I recall there were some people who were the only ones in their decile. And it's stuff like that which shows how easy it is to correlate supposedly anonymized data.
There is no "just" when it comes to this stuff. It's way harder than anyone intuitively thinks it is. I didn't participate last year and I have no interest in participating this year if releasing individual responses is an option, even if there's an opt-out.
Consider this for each census question; many questions that are "choose one" might benefit from using a "choose all that apply" format.
As an addition to this would asking about operating systems in more depth just be a mess with the small number of responses? As in asking "Windows", "macOS", "Linux", or "BSD" and then asking with a freeform text box what actual operating system "Windows 7", "Temple OS", or "Ubuntu".
Done and dusted.
I think using a set of umbrella terms is better. Otherwise this group quickly just becomes "other answers __%" rather than counting these actual identities.
This holds true for all categories: If there are set options for the most common political views, and you choose a write-in option rather than a somewhat less precise and more general term supplied, that's the most effective way to have your view under-counted and therefore underestimated.
That's kind of the problem with aggregation of data, no matter what you do you'll lose some detail of the data, and people will have to deal with the fact that they weren't allowed to enter the way they feel about something in the way they wanted to. Especially with something touchy about gender where the range of identities is far and wide, especially on a left-leaning internet forum.
If it helps, I don't think adding a free-form field for gender is going to hurt much, as on last years census, only 4% of all people said they were non-binary. You can have whatever discussion about that you want, but they are a minority within a minority and I don't think that in this case they would dilute the data as much, as for example adding a free-form field for political conviction would.
It might be interesting to set up a preliminary survey that's more free-form, to gather potential answers and see what people are interested in.
Something like:
Then maybe share it here as a word cloud and use that data as a starting point to build census questions.
Well, the gender question has a freeform answer field now, so anyone can enter whatever they want. If you want your gender to be Communism, you can. So point 1 would be kind of moot.
However the second point would definitely be interesting. Last time we did it with an 8values test, but what about letting people enter their political position in a free-form text field? It's going to be a nightmare to analyse and of course you have people often describing themselves as something while actually being something else based on their political convictions.
I'm kind of curious, for those that are mods or ex-mods from reddit, the approximate number of subscribers they moderate.
I keep hearing how many mods/ex-mods there are here, just curious I guess.
Hmm... How to word this question would be difficult.
I currently mod several subs on reddit, most of them "small" (largest is 500k subs) compared to the defaults (even if there aren't technically defaults any longer), but I was a mod of a couple of defaults at one time along with some other non-default massive-for-the-time subs.
What about If you were a moderator on Reddit, what was the peak amount of subscribers you moderated?
The question of course is, what do we do with that data? Can you have a discussion about it? Or would that maybe just be suited best for a separate Tildes thread with to discuss that specifically?
Maybe for people that use Tildes on mobile, if they use it with a web wrapper app like Hermit or Native Alpha, use a home screen shortcut from their browser, or just use a browser. Nothing important, just potentially interesting. Maybe.
I recommend going through the questions and putting in an "It's complicated" option. (Not just gender.) Questions are often more ambiguous than they seem to the person who wrote them, and outliers are interesting.
(On the other hand, outliers are also identifying, so not everyone will want to explain further.)
Not a question for the survey/census itself, but when posting results, would it make sense to have 2 threads (main and freeform/free-form)? One thread to act as the main topic for the census results with a link to the second topic which more specifically addresses the free-form questions.
It sounds like this time around there might be more free-form questions, and it might be easier for comments to discuss them separately from discussion about the census in general. Are stickied comments a thing in progress on Tildes?
Looking at last year's results, I think with just the 3 pastebins about Tildes, the answers seemed overwhelming (although many of the answers were kind of similar), so ideally there is a better way of handling that. Might be a task to delegate. I'm not entirely sure what the best way to do this sort of thing is.
As an aside, I imagine making nice charts (pie/bar/whatever) is difficult with the amount of different answers?
Depends on the amount of replies I'll get. I don't think sticky replies are a thing, maybe you're right and separate threads are the way to go.
I'm still on edge about more freeform replies. On one hand, they give you a way to precisely say what you want. On the other hand, if I have to attempt and extract the core meaning from such a reply to create a graph, the advantage of the freeform reply is lost anyway. Though what I might do this year is offer the most popular solutions to last years freeform replies as options to select.
Do you have a list of all questions you are planning to ask this year? It would be helpful to have in order to provide any additional feedback.
I have not yet formulated them, I was meaning to make a second post with the (planned) 2020 form to garner additional feedback. This was more of a prelimary round to see if there were general issues to address.
I know personal politics are derived from values, but I think questioning that emphasizes what people value in a way that doesn't seem to directly reference politics is more interesting. With correlations to be made afterward, I guess...
Oh, and I think knowing how many generations a family has been in the country they reside (on top of ethnic background) is useful.
I doubt most people will know that offhand.
Certainly. But, if known, I think it adds to the "picture", so to speak. And it may prompt some folk to look into their family history, which can be enlightening. And scary...
Out of curiosity, how do you answer this question? Just looking at my 4 grandparents, one was an immigrant, one has at least some ancestors going back several hundred years in the country, and the remaining two I have no idea. How many generations has my family been in the country?
250 was pretty low yeah, and I don't know how many accounts have been created, but tbh when writing comments I always see the same people, I don't think the active userbase of Tildes is very big.
I think that's fairly interesting, but I'm wary of freeform questions because they are hard to aggregate besides basically reading them all and giving you a summary. I did release the feedback section, but I think it's just very hard to discuss these things because for personally the workload increases immensely, and if I just release them all, no one will discuss it because no one wants to read a few hundred responses just to discuss other people's love life.
Please don't add these question,, please.
I agree, please don't.
Fair enough.
I guess it's easier to request something when it doesn't apply to you and you don't have a lot of stuff to share about yourself in general.
I'm assuming sparing the details/context and only asking a yes or no question doesn't count, right?
A'ight.
I guess I did say "and if we're feeling ballsy" in my original comment as a way to acknowledge that's kind of extreme and the doesn't in "only asking a yes or no question doesn't count" shows that I'm asking for clarification rather than a pretty tone-deaf question.
Huh? From what I can tell, anonymization doesn't apply just to the freeform questions, it applies to the entire data set, right? The only question I said would be freeform was the hobby question, and for the other ones I even gave a summary of the options that I think would make sense, that you quoted?
EDIT: Oh yeah, and please use a color pallette when you show people's location, please.
I think @Grzmot is just saying that freeform answers make data analysis hard, because people word things differently. If there is a question “What hobbies do you have?”, three different users could answer “Music”, “playing an instrument”, and “guitar”. Those answers should all ostensibly be included under one category when presenting final results but that is hard to do programmatically because it’s not simple to write a program that recognizes those answers as different forms of the same general hobby. So the only thing to do is manually go through and categorize or summarize things which is subjective and time consuming.
Fair enough. This question has come around a few times and the threads here been very long.
The thing is, it seems really hard to sum up something like hobbies into a 30-question (upper limit) or so format, hence why I think it should be made a free-form. Maybe we might want to put that through the process /Omnicrola described here?
Because I can't come up with a characterization of hobbies off my head.