Please help me become a python backend developer!
I am looking for an effective roadmap to become a python backend developer. I am from a non-CS background. I can buy a couple of courses on udemy, if the need arises. TIA!
15
votes
I am looking for an effective roadmap to become a python backend developer. I am from a non-CS background. I can buy a couple of courses on udemy, if the need arises. TIA!
Some of the things I'm concerned about are browsing across unconnected instances - will I need twenty accounts to follow all of the groups? What is the likelihoood of an instance dissapearing? How do you gauge the culture of an instance? Is the https://redditmigration.com/ actually being populated by real admins of those subreddits? Are there any gotchas from joining an instance that I should be aware of? Thanks!
My typical approach is one that I believe is pretty common: Reading the response header for current count and waiting if the limit is reached.
However, I am currently working with a couple of APIs which don't implement that and are currently set up with rate limits on an honesty system.
Is it a case of throwing sleep statements into you code, or using some kind of "bucket" and "lock" system?
I'd be interested to see any simple implementation people have used (the simpler the better).
My main needs are:
I don't need a beefy GPU (the iGPU will be more than I need) or lots of CPU performance (I'll probably pick one of the cheapest compatible CPU).
AM5 is still pretty expensive and the cheap(-ish) motherboards mostly only have 4 x SATA so I would need an extension card. But I'm considering it because 5nm vs 7nm should improve the power efficiency, right? What kind of improvements should I expect there?
Are there any other reasons to go for AM5? I might prefer it for emotional reasons (the lastest and greatest always feels better) so I could use some input from kind strangers.
I could also just wait a bit longer. When should I expect the low-end AM5 comonents to become cheaper?
Please help lol
| Type | Item | Price |
|---|---|---|
| CPU | Intel Core i7-12700KF 3.6 GHz 12-Core Processor | $239.99 @ Newegg |
| CPU Cooler | Noctua NH-D15 chromax.black 82.52 CFM CPU Cooler | $119.95 @ Amazon |
| Motherboard | Asus ROG STRIX Z690-A GAMING WIFI D4 ATX LGA1700 Motherboard | $299.99 @ Amazon |
| Memory | \*Corsair Vengeance LPX 32 GB (4 x 8 GB) DDR4-3200 CL16 Memory | $94.99 @ Amazon |
| Storage | Samsung 970 Evo Plus 1 TB M.2-2280 PCIe 3.0 X4 NVME Solid State Drive | $54.99 @ Amazon |
| Storage | Seagate Barracuda Compute 2 TB 3.5" 7200 RPM Internal Hard Drive | $49.99 @ Amazon |
| Video Card | MSI RTX 3060 Ventus 3X 12G OC GeForce RTX 3060 12GB 12 GB Video Card | $289.99 @ Amazon |
| Power Supply | Corsair RM750 750 W 80+ Gold Certified Fully Modular ATX Power Supply | |
| Prices include shipping, taxes, rebates, and discounts | ||
| Total | $1249.88 | |
| *Lowest price parts chosen from parametric criteria | ||
| Generated by PCPartPicker 2023-06-06 10:27 EDT-0400 |
I currently don't know anything about programming so am considering picking this up on the side in case I loose my current job and need a backup plan. Anyone knows any good books or online courses or anything else for self-learning?
My friends said programming is too broad a subject and what you need to learn depends heavily on what fields you want to go in, which I'm ashamed to admit also know nothing about. So I guess I need some career advice too if possible.
Tildes is pretty technically minded place, so I figured this would be a good place to get some advice. Programming is something I've taken a class or two on (though it's been long enough that I'd like to start from scratch) and I think I have some aptitude for it. The possibility of working from home is also very appealing. However, there are a ton of resources out there, and "learn to code" has been a thing for a while now. Is self-teaching or one of those coding boot camps a viable way to get started in the field? And if so, what are some good resources and practices for getting there? I have some money available, but a degree would be expensive both time and cost wise.
Hey everyone!
Sorry if this is a long post, but I've done my research and I would like to make a few questions.
I've decided that I would like to buy a NAS mainly to storage all of my documents, photos and videos, so that, I can access them from multiple devices and also use it to upload important documents to Backblaze B2. Then, I've actually discovered that I can install a few Docker containers and I could use it as a media server (Jellyfin) and serve the content to my Apple TV (neat!).
I considered a QNAP (better hardware for the price) but everyone recommends Synology instead (because of the stronger security and better overall software), but to be honest, I'm not sure what should I get.
My budget would be to buy a NAS (without counting the disks) below €1000. Ideally, €500-600 but I don't mind stretching to the €700 mark, if it is really worth it.
Spoiler alert: I think, it should be the DS920+ (4-bay) or the DS1520+ (5-bay). I think a NAS above 4-bay is better for future-proofing.
Looking here in Germany at price comparators, I could buy the DS920+ for €663 and the DS1520+ for €750. But these prices seem to be at an all-time high :(
Questions & Assumptions:
0. I'm not sure if the price difference of about €100 is worth the premium to get the 5-bay model. There are only two differences between these two models: The 5-bay has one extra slot, and it has 4x 1 Gbe LAN ports instead of 2x 1 Gbe. All the rest is the same. What is your opinion?
1. I've read that if you run a few containers (~10) it consumes quite a bit of RAM (~3 Gb), so it should be ideal to have at least 8 Gb. This is the reason I've said that I think I can only choose the DS920+ or DS1520+. Looking at official Synology resellers, these models, seem to come already with 8 Gb, and they are within my budget. Is my research wrong?
2. These two models, have an encryption engine. I think this is necessary to encrypt my files before sending them to Backblaze, or?
3. A lot of people seem to say to simply pick Synology's hybrid RAID setup called SHR-1 or SHR-2. I would go the easy way here and pick one of those two. Would you think that is a bad idea, and it is better to pick a specific (standard) RAID? I've read about the long long long RAID rebuild that could happen in some situations, and picking the "right" RAID could decrease the rebuild in days (or weeks!!!!).
4. In case, I choose a NAS model with Nvme cache slots, most people say it is not worth it to use if you are not running Virtual Machines and the SSD’s "burn" really fast. I have no interest on VMs.
5. Most people say to pick an Enterprise (Server) HDD instead of a NAS HDD mainly because price is similar in some cases and Enterprise has longer life and warranty. I should also pick a CMR HDD which is helium filled. 5400 rpm would be preferable to 7200 rpm because of the noise. Sadly, all Enterprise HDD's and most of NAS HDD's are 7200 rpm. Is the noise difference that big? The NAS will be in our living room.
6. Is 8 TB still the best cost per Terabyte?
7. I was extremely sad to hear that the Hitachi hard drive division was bought by WD. I've had lots of misfortune with WD drives (and let's not forget the debacle with the SMR and CMR drives) and I would prefer not to give money to them, but, nevertheless, I'm still tempted to buy the Ultrastar drives that belonged to Hitachi. Does anyone know if WD kept the components, manufacturing processes, staff, etc., that made these brilliant disks?
8. Following the HDD topic, what is your experience with Seagate or Toshiba drives?
9. These two NAS models have the same Intel Celeron CPU, which supports hardware transcoding. To be honest, I don't know in which cases would that happen. It seems if I use Infuse on the Apple TV it would never transcode (and instead direct play) because Infuse would do the transcoding in software. Should I take in account that hardware transcoding is a must-have or a nice-to-have?
10. Would you recommend having a CCTV system connected to the NAS? Should I dedicate one entire HDD just for the NVR system? Would a standalone NVR device be better?
11. My last question is: Should I just wait for the new model of the DS920+ or DS1520+? The 20 means it was launched in 2020 (in Summer specifically) and it seems Synology refreshes the model every two years., that means, a new model would be available in Summer this year. Most people say it is not worth the wait because Synology is very conservative in its model updates/refreshes. People are saying that a better CPU will be of course available (do I even need that for my use cases?) and probably upgrade the 1 Gbe LAN ports to 2.5 Gbe or 10 Gbe (10 Gbe I really doubt it). I've read that a 4K stream does not fill a 1 Gbe bandwidth, and you could theoretically have three 4K streams in a single 1 Gbe connection. If all else fails, I could just do a link aggregation of the two ports to be 2 Gbe, or?
12. Anything I'm forgetting? Should I be careful with something in particular?
I know I should buy a UPS too, but I think I'll create a separate post regarding this topic because I would also want a recommendation regarding a UPS for my other devices.
I know that I could actually build my own NAS and use Unraid for the OS. Furthermore, I'm just at a time in my life with too much on my plate (baby and small child) and having something that just works is preferable. When they are older and more independent, I'll have more time to investigate this option :)
Again, sorry for the long post. Thank you everyone!
I finally got around to upgrading my mom’s computer (an Asus laptop from 2015) from Windows 8.1 to Windows 10. I’ve already deleted a few apps she won’t use (e.g., Xbox) and disabled/stopped some unneeded services. What else can I do to keep her computer fast? Particularly interesting in more services I can disable and the best browser/ad blocker combo. Thanks y’all!
Title says it all. Bootstrap+jquery has been my default route and path of least resistance when it comes to web development. Perhaps because I'm coding since a long time and belong to the old school when modern libraries like react weren't yet invented yet?
I had tried to meddle with Angular.js 1.0 back in those days but was soon disillusioned! It was cool and cutting edge but highly opinionated. It tried to do so many things under the hood that I soon quit the effort and the word "Angular" was stigmatized in my mind ever since! I don't know how different today's typescript based Angular is but that stigma or phobia prevents me from even looking at that direction!
React is another cool technology which everyone is talking about and I'm sure it has some merits. But I'm not sure exactly what React brings to my development workflow which jquery doesn't already do. Can you tell me some specific advantages or pros of react over jquery which can motivate me to learn the former and let go of the latter? What should I do?
I finally decided to accepted that my interest in working and playing with computers and servers is worth to spend some money on. So I ditched my old box in the corner and with it all my fights with my ISP, their NAT, dynamic DNS and all that and got myself a VPS and 1 TB storage solution for less than I would have paid a static IP with my ISP.
Best decicion ever :-)
So I'm getting into Docker a bit, just because it's just so easy to get Nextcloud running. I used native Caddy as a reverse proxy, because if I got this "machine" there I will use it for other things as well, so make it right from the beginning. And I used native b.c I did not yet understand bridge/host mode and installing caddy native seems easier.
Then I fought for one day with CIFS and the nextcloud gui to get the semantics right to get my storage solution accepted as external storage.
Then I set up Jellyfin with Docker because why not. As well through caddy.
Then I fucked something up and was like, fuck it, lets start again this time for real :-P
I wiped my VPS clean (chose ubuntu again) set up and hardend ssh + sudo installed Docker, and then I found out about docker rootless and in the docker docs it's mentioned that it is/might be more secure, so I set up docker rootless and installed all the rest again.
And then I was like, hmm, do these Docker Images/Containers update themself? Like snap did?
It seems not, so I looked for a solution and found watchtower. And now I wasted another day trying to get watchtower to run, and I just can not.
I tried so many variations of the run command now most recently I tried:
docker run \
--name watchtower \
-v ${DOCKER_SOCKET_PATH}:/var/run/docker.sock \
containrrr/watchtower
time="2023-01-20T01:17:41Z" level=error msg="Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?"
time="2023-01-20T01:17:41Z" level=info msg="Waiting for the notification goroutine to finish" notify=no
/run/user/1000/docker.sock exists, I own it, i tried connecting to it through docker -e and containrrr/watchtower --host "unix:///run/user/1000/docker.sock"
I dont now what to try more and I'm at my end with my ddg-fu as well.
And now while proofreading this, I read everything again and decided to try something again and it just worked...
docker run \
--name watchtower \
-v /run/user/1000/docker.sock:/var/run/docker.sock \
containrrr/watchtower
seems like the environment variable was not set. But I'm shure I tried that before and it did not work... ghost in a machine :-)
So thats where I'm at. I have to say it was a lot of fun and doing and learning all that tingled my brain in a funny way :-)
But now I have some questions for my much more experienced Tildes-friends:
I very much appreciate all further/other advise, tricks, recomendations, questions and discussion as well :-)
(apologies if this isn't the correct place to ask, I'm just a bit out of ideas)
(content warning for abusive parents)
I have a friend who's abusive parents track her location using the stalkerware app life360.
she currently runs graphene os (android 13) on a pixel 7 pro.
in my past android experience there are plenty apps that can spoof your location via developer settings. however they all crash on android 13 (or at least on graphene..)
see below (none of these work, and they also crash on my android 13 phone, but they have worked for me in the past on like android 9):
https://github.com/mcastillof/FakeTraveler
https://github.com/wesaphzt/privatelocation
https://github.com/warren-bank/Android-Mock-Location
https://play.google.com/store/apps/details?id=com.lexa.fakegps&gl=US
if there are no functioning apps that will do this. do you know any other solutions? on other android roms or with root with magisk / xposed? obviously this is less secure than graphene os but the current problem is her parents more than anything else.
we r also considering a secondary phone just for the stalkerware which can be opportunistically left in innocent places. or just killing the life360 app on occasion when needed. or just letting the phone die when it needs to. But not sure how obvious this might be to the abusers. any insight is appreciated.
(suggestions like "leave her parents" are good but far easier said than done and while it will eventually happen its not feasible at the moment. That being said if you can provide detail suggestions are welcome)
Thanks :)
I'm primarily a freelance backend dev and for the first time venturing on full-stack development of a non-trivial web app on my own, hence I needed some guidance.
I've got all the backend stuff in php/mysql covered, I just want to know what's the best way to create a dashboard (with left sidebar) considering various aspects like long-term code maintenance and support, robustness, etc. Looks don't matter that much as it's a CRUD app but obviously, better is more appreciated.
Based on my research until now, AdminLTE seems to be the most popular way of doing it among most devs although a few others like material and coreui also seem to have some street cred.
But another approach I'm considering apart from AdminLTE is to just use pure bootstrap and fiddle up my own sidebar using something like this. That way, I won't be tied to just one Bootstrap version which is used by AdminLTE (v4.6) and troubleshooting will be much easier through google search and StackOverflow. What do you guys think is the right approach?
Hello everyone,
I usually do my own research, and then I try to find multiple matching results and afterwards, read specifically in detail about each recommendation, but, I have to be honest that for UPS recommendations that I’ve seen, it seems to be a very personal recommendation depending on the wattage and connected devices.
First of all, most people recommend CyberPower or APC, but I’ve also seen some recommendations for Eaton. Is there any other brand that I should be looking into?
The devices I would like to connect to a UPS would be: desktop, TV, Apple TV, NAS, router and probably my Nintendo Switch.
There are some general things I've found out while searching that I think I would like some confirmation:
How would I choose a UPS? Do I need to see the total wattage of all my devices and then pick the UPS accordingly? Anything I'm missing?
My budget would be up to €100 or €150 in case it is really worth it.
Thank you in advance for all replies.
Right now I've got a shitty WD EX4100 and everything was sort of running along nicely with docker and all, but today it rebooted and decided that it didn't want to do anything with docker anymore. I got the thing before I got into Linux and its time to move on.
Someone locally is selling the following for $250CAD
All I run are the following:
I don't need the drives that come with it. I'll be putting in 4x 4TB WD Reds. Right now the box is running Open Media Vault 6, so I'll give that a swing, otherwise it'll just be Ubuntu server.
How does this sound? I'm not opposed to spending some money on a new NAS, I just want something simple that I don't have to fuck around with too much.
I ended up going with the HP Proliant
OS: Ubuntu 20.04.3 LTS x86_64
Host: ProLiant ML310e Gen8
Kernel: 5.11.0-43-generic
CPU: Intel Xeon E3-1230 V2 (8) @ 3.700GHz
GPU: 01:00.1 Matrox Electronics Systems Ltd. MGA G200EH
Memory: 32GB
It's pretty good so far. Thanks everybody!
Is anyone here familiar with crawling the web? I’m interested in broad crawling, rather than focusing on particular sites. I’d appreciate pretty much any information about how this is usually done, and things to watch out for if attempting it.
Hi all. I am asking this open-ended question (bottom of this post) because I am considering making contributions to an open-source project that would directly benefit me and other users.
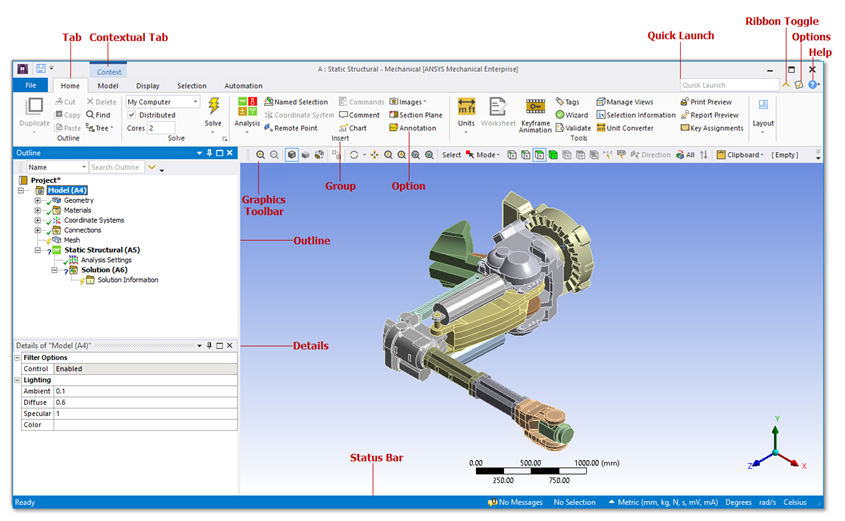
I have worked with an engineering simulation software called Ansys MAPDL basically everyday for the last 4 years, in both an academic and a professional capacity. It's not necessarily relevant whether you are familiar to that program to participate in this discussion. The relevant thing is that the GUI for MAPDL is written in Tcl/Tk and I don’t imagine it is going to be modernized (because of more modern, but distinctly different, replacements). This is a screenshot of the GUI for reference.
The power of the program is not its GUI, but the scripting language that can be run to setup and solve simulations. The program name is really the scripting language name, Ansys Parametric Design Language (APDL). It's somewhat like Matlab. The program also offers an enormous amount of control when compared to the more modern GUI that's been released, since the modern GUI holds a totally different philosophy.
The older GUI is really helpful in certain circumstances because it will spit out a file containing commands that were used in the session. This is a great demonstration of how to run a command or use a setting/config command, but a lot of newer features are buried in the documentation and aren't available in the older GUI.
I know the MAPDL language very intimately, but my experience beyond it is limited to some Perl scripting, and a bit of Python exposure.
Recently, Ansys started supporting an open-source Python project called PyAnsys. MAPDL is otherwise fully closed source, and this is really the only public-facing API. PyAnsys has basically converted a lot of MAPDL script commands to a pythonic format, hence Python can now be used to interact with MAPDL. This is great for several reasons, but is limited regarding interactivity. Interacting with MAPDL via Python is basically happening in a fancy console via Jupyter notebook or IDE like Spyder. Certain commands will bring up Python-based graphics displays of solid models and results plots, but there isn't a dedicated GUI open all the time.
My question is whether it is feasible to write a frontend GUI to a bunch of python commands. If you were going to do it, how would you do it? What might you write it with? Would you even do it? Is this a stupid endeavor?
Let me start by saying this is a space I am not at all familiar with. I didn't grow up with IRC, my first text editor was Sublime (I'm not from the "EMACS vs. VIM" generation,) so I feel kinda outta touch with what all is going on.
Is there a winner? I feel invested in this topic after seeing a whole slew of posts, blogs, and medium articles posted all over Reddit and HN breaking down how these folks have personally been impacted over the past month or so. It seems to have died down which leaves me with the question of what the outcome was. An even 50/50 split? Libera destroying Freenode? Or Freenode able to hold onto users by successfully preventing efforts to organize a transition?
Without being in the Freenode community, I don't have a feeling for whether Freenode is dead, Libera Chat is "winning" and I don't think there's a good way to get metrics either.
Anyone in this world who can help the uneducated out on the outcome of all of this?
I'm setting up a server with nextcloud, plex, matrix and some other things I don't yet know, for some friends and family, (about 20 people if I get lucky)
and now I heard of a thing called single sign on/unified login. (Login to different services with the same user/pw and/or login once, access to all services)
so far I found out about Keycloak https://en.wikipedia.org/wiki/Keycloak
is this what I'm looking for? does anybody have experience in this? Are there other/better/simpler solutions for this?
I recently set up kubernetes to run on an old laptop. The goal was two-fold, 1 learn kubernetes and 2 setup an instance of nextcloud. I've managed to set everything up with cert renewals for my domain and enabled dyndns in case my provider changes my ip. All well and good and quite nice learning experience! Now I would like to also start running my own email server and have some questions. Is ther any that have a helm chart that is easy to setup in kubernetes? Since I am running this from home I imagine I'm more likely to be classified as a spammer. What can I do to minimize the likelihood of that? I read somewhere about reverse DNS, but not entirely sure if it is possible to do given I am running it all at home via a regular ISP.
I have a Xiaomi Redmi 4X device with 2GB RAM and 16GB on-device storage.
Yesterday, I setup PostmarketOS on it, and it works well enough. WiFi and display work well, although no 3D acceleration and no telephony at all. As such, now it is just another device on my home network, except that I can ssh into it to do some basic stuff. Right now it is setup as a Syncthing node to backup my Keepass db and personal knowledge base written in org-mode, but I would like to use it further, and looking for ideas.
Two things to consider, though. First, I don't want it to overcharge and bust the battery. Before when it was on LineageOS, I had a magisk module acc so it would charge only 40-80%, and is largely the reason why the battery holds up pretty well after 5+ years without swelling. I will take further look into it over coming weekend and try to make something like it for the alpine kernel included in PmOS. Second, while on charging the phone keeps vibrating repeatedly. I have no idea how to fix that one, but would like to strat given pointers. (I have never done kernel dev in my life)
So, any ideas on what I can use this extra computer in my metaphorical basement welcome. Thanks in advance.
It is late... and I am pretty much finished with migrating to a new VPS provider. I got rate limited with two domains, but I'm running everything through Cloudflare. Do I need to bother with LetsEncrypt on the VPS itself? When I check the domains, the certs from CF are working nicely.
This is my first time using CF.
Quick edit while I pretend I can sleep.
I’m thinking that CF will cover me for 443 and route all traffic there. I’ve got wildcards set for domains with services that require other ports — which is working. All CF is doing is caching my sites, right?
I've been learning a bit more Python, going through a Udemy course to expand my skills a little. One of the programs the course guides you to make is a little dictionary, but it currently only runs once and then quits.
I'd like to adapt it to use a nice TUI that keeps itself open until the user specifies they want to quit, using something along the lines of npyscreen. However, this library uses classes, and that's not something I'm yet familiar with. I'd rather have an understanding of what classes are, how they work, and why to use them before I take the plunge and start fiddling around with npyscreen (although I'd be interested to hear if you think that I should Just Do It instead).
Can anyone give or point me towards a good explanation of the what, how, and why of Python classes? Or better yet, a tutorial that will give me something to write and play with to figure out how it all fits together?
Thanks!
I don't need answers so much as an idea of where to start.
Essentially, I have a Google Sheet that uses importjson.gs to pull from the following APIs
I also use another script to scrape Letterboxd for ratings.
This works well, but sometimes it'll time out or I'll hit urlFetch limits that Google has in place.
Basically, I'd like to have a text file (input.txt) where I pop in a bunch of titles and year or IMDB IDs, then the script runs and pulls set endpoints from all of these, outputting everything on one line (a pipe as a delimiter.)
My thinking is that I can then pull that info a sheet and run all of the formatting, basic math, and whatever else so it suits my Sheet.
I have a feeling I'll be using requests for the JSON and beautifulsoup for letterboxd -- or maybe a module.
Can anyone point me in the right direction? I don't think it'll be too difficult and should work well for a first python project.
I still mainly use Windows, although I've dual-booted Linux a few times and I have Linux Mint on an old laptop right now. One thing I've never understood about Linux is all the different distributions - their different reputations and why they have them. What is the mechanical difference between using one distribution of Linux and another? Or are the differences usually not mechanical?
For example, Ubuntu and Debian seem to be large families, meaning that a lot of other distributions are based on them (using packages built for them in their package managers at least) as well as being popular distros on their own. But what's different between the two of them, and between each and the other distros based on them? (and what's similar? I gather they all use the Linux kernel at least!)
I also know that people are quite opinionated on their choice of distro, I wondered what reasons people had for their choice. What things are easier or harder for you in your distro of choice? Is it mainly day-to-day tasks that are important or more how the OS works underneath? How much difference does your preferred distro make?
For myself, I've only used Kubuntu (though not much) and Linux Mint, which was mainly for UI reasons, and particularly for the latter, ease of use for someone used to Windows (at least that was what I found years ago when I first looked into it).
Though I doubt I'll ever fully move away from Windows I would like / need to have access to a Linux OS, so maybe this will help me to know what is important to look for. But I also hope it'll be a useful and interesting discussion topic. Also, there are some previous discussions on the latter question so I'd be more interested in learning about the main topic.
also, please do add more tags
I see some people using NixOs on their servers. I would like to try it out to self host some services and learn about NixOs.
I use hetzner and they have an NixOs iso available so I can just use that to install NixOs. But how do people manage remote instances of NixOs? They would just use ansible or something like it, to run nix on the host, or is there a better way?
Thanks
I've just read a journal from someone on another site saying that they wished there was a blacklisting system which stopped them seeing submissions from, to or about certain other users in their feed, as it is potentially trauma-inducing for them to log in and keep seeing them come up. I assume that the person looking for this blacklist isn't realistically able to just leave the site, because it's the most populous of its kind and serves as an art portfolio or source of income.
Is this, or something like it, actually possible to do with custom ad-blocker rules, or do they need to just wait for the site's admins to get around to it?
I'm attempting to provision two mirror staging and production environments for a future SaaS application that we're close to launching as a company, and I'd like to get some feedback on the provisioning script I've created that takes a default VPS from our hosting provider, DigitalOcean, and readies it for being a secure hosting environment for our application instance (which runs inside Docker, and persists data to an unrelated managed database).
I'm sticking with a simple infrastructure architecture at the moment: A single VPS which runs both nginx and the application instance inside a containerised docker service as mentioned earlier. There's no load balancers or server duplication at this point. @Emerald_Knight very kindly provided me in the Tildes Discord with some overall guidance about what to aim for when configuring a server (limit damage as best as possible, limit access when an attack occurs)—so I've tried to be thoughtful and integrate that paradigm where possible (disabling root login, etc).
I’m not a DevOps or sysadmin-oriented person by trade—I stick to programming most of the time—but this role falls to me as the technical person in this business; so the last few days has been a lot of reading and readying. I’ll run through the provisioning flow step by step. Oh, and for reference, Ubuntu 20.04 LTS.
First step is self-explanatory.
#!/bin/sh
# Name of the user to create and grant privileges to.
USERNAME_OF_ACCOUNT=
sudo apt-get -qq update
sudo apt install -qq --yes nginx
sudo systemctl restart nginx
Next, create my sudo user, add them to the groups needed, require a password change on first login, then copy across any provided authorised keys from the root user which you can configure to be seeded to the VPS in the DigitalOcean management console.
useradd --create-home --shell "/bin/bash" --groups sudo,www-data "${USERNAME_OF_ACCOUNT}"
passwd --delete $USERNAME_OF_ACCOUNT
chage --lastday 0 $USERNAME_OF_ACCOUNT
HOME_DIR="$(eval echo ~${USERNAME_OF_ACCOUNT})"
mkdir --parents "${HOME_DIR}/.ssh"
cp /root/.ssh/authorized_keys "${HOME_DIR}/.ssh"
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
chown --recursive "${USERNAME_OF_ACCOUNT}":"${USERNAME_OF_ACCOUNT}" "${HOME_DIR}/.ssh"
sudo chmod 775 -R /var/www
sudo chown -R $USERNAME_OF_ACCOUNT /var/www
rm -rf /var/www/html
Installation of docker, and run it as a service, ensure the created user is added to the docker group.
sudo apt-get install -qq --yes \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo apt-key fingerprint 0EBFCD88
sudo add-apt-repository --yes \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get -qq update
sudo apt install -qq --yes docker-ce docker-ce-cli containerd.io
# Only add a group if it does not exist
sudo getent group docker || sudo groupadd docker
sudo usermod -aG docker $USERNAME_OF_ACCOUNT
# Enable docker
sudo systemctl enable docker
sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
docker-compose --version
Disable root logins and any form of password-based authentication by altering sshd_config.
sed -i '/^PermitRootLogin/s/yes/no/' /etc/ssh/sshd_config
sed -i '/^PasswordAuthentication/s/yes/no/' /etc/ssh/sshd_config
sed -i '/^ChallengeResponseAuthentication/s/yes/no/' /etc/ssh/sshd_config
Configure the firewall and fail2ban.
sudo ufw default deny incoming
sudo ufw default allow outgoing
sudo ufw allow ssh
sudo ufw allow http
sudo ufw allow https
sudo ufw reload
sudo ufw --force enable && sudo ufw status verbose
sudo apt-get -qq install --yes fail2ban
sudo systemctl enable fail2ban
sudo systemctl start fail2ban
Swapfiles.
sudo fallocate -l 1G /swapfile && ls -lh /swapfile
sudo chmod 0600 /swapfile && ls -lh /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile && sudo swapon --show
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
Unattended updates, and restart the ssh daemon.
sudo apt install -qq unattended-upgrades
sudo systemctl restart ssh
You can assume these questions are cost-benefit focused, i.e. is it worth my time to investigate this, versus something else that may have better gains given my limited time.
ss or lynis (https://github.com/CISOfy/lynis) to perform server auditing? I don’t have to meet any compliance requirements at this point.
ssh into our boxes, then the likeliest risk profile for unwanted access probably isn’t via the authentication mechanism I use personally to access my servers.
Hi! I've heard tilderinos talking about the gemini-verse on some other posts; I tried it out this evening and it honestly felt strange browsing in terminal and even stranger navigating the web without search engines. I was wondering if anyone had a gentler introduction than the official site? I feel like I've got a ship, but no map to this new verse.
Suppose I am trying to iteratively produce a completed image from some subset using a combination of convolutional/DNN methods. What Image norm is best?
The natural (for me) norm to ascribe to an image is to take the bitmap as a vector with L2. If the input image is anime or something else, the uniform coloring makes this very likely to be a good fit in a low dimension - that is: no overfitting.
However: pictures of fur. Given a small square, the AI, set to extrapolate more fur from that single image, should be expected to get that stuff right next to the given subimage right, but further away, i want it to get the texture right, not the exact representation. So, if the AI shifts the fur far away from the image left by just the right amount, it could get an incredibly poor score.
If I were to use the naive L2 norm directly, I would be guaranteed to overfit, and you can see this with some of the demo algorithms for image generation around the web. Now, the answer to this is probably to use a fourier or a wavelet transform and then take the LN norm over the transformed space instead (correct me if I'm wrong.)
However, we get to the most complex class: images with different textures in them. In this case, I have a problem. Wavelet-type transforms don't behave well with discrete boundaries, while pixel-by-pixel methods don't do well with the textured parts of images. Is there a good method of determining image similarity for these cases?
More philosophically, what is the mathematical notion of similarity that our eye picks out? Any pointers or suggestions are appreciated. This is the last of two issues I have with a design I built for a Sparse NN.
Edit: For those interested, here is an example, notice how the predictions tend to blur details
Last Thursday, at my workplace, we rolled out a software upgrade across the company. The server side was upgraded overnight to ensure there was minimal downtime, and we had instructions for users posted on our Intranet (pinned to the top for the next 4 days), on exactly what they needed to do to run the upgrade on their PCs and ensure everything was working correctly.
The instructions were written with the help of my 4-year-old to ensure it was clear enough for anyone to read and follow along.
I still received at least 40 messages and emails from people complaining the upgrade didn't work or that certain Outlook plugins are now missing (which was covered in the instructions).
It is very frustrating to take the time to ensure things go smoothly and write what even my 4-year-old thought was clear instruction, and still have a third of the company not be able to figure it out?
This is not meant to be mean hearted in any way, I genuinely would like some advice or tips on how I can improve on this the next time around.
Thanks.
Which signs have you learned to recognize?
I'm working on an application that allows a user to view playlists belonging to a particular radio show and stream/download/favourite the tracks in them. It has 4 core entities: User, Show, Playlist and Track.
To be able to reference a playlist belonging to a particular show. I gave those playlists the same uuid as the show they belong to. A few questions though.
For any experienced database designers out there, how would you structure this data? What would you consider in designing the schema and why? If I did go with 4 tables only, presumably there would be performance implications given the potential amount of data in any one of those tables, particularly tracks. If that is the case, how best to structure this kind of thing with performance in mind? Thanks in advance for any help :)
For reference, in case it's of importance, I'm using sqlite3.
Hey everyone,
I've been programming for some time now but notice without any formalized education in CS I often get lost in the weeds when it comes to developing larger applications. I'm familiar with the principles of TDD and SOLID - which have helped with maintainability - however still feel that I'm lacking in the ability to architect a properly structured system. As an example, I'm currently developing a flask REST API for a website (just for learning purposes). This involves parsing a html response and serializing the result as JSON. I'm still quite unclear as to structuring this sort of thing. If any more experienced developers could point me in the right direction/offer up their opinion I'd be very appreciative. Currently I have something like this (based - I hope correctly? - on uncle bob's clean architecture).
Firstly, I'm defining the domain model. i.e the structure of the API response. Then, from outside in.
If you got this far, thanks so much for reading. I really hope to hear the opinions of more experienced devs who can steer me in the right direction/correct me should I have misunderstood anything.
I am a fullstack developer that spends a good portion of my time building out complex User Interfaces, and the rest building out back-ends for that software. In my opinion the current method that my company uses for a designer to developer hand off is a bit lacking in efficiency.
The current method is usually a designer will provide a developer with a Photoshop (or very occasionally an Illustrator) file containing the entire applications design. It is then up to the developer to export assets (both quick exporting things as pngs, going through and separating shadows from assets, or creating assets from the layers provided) and dig through the file to determine fonts and placement of items.
Is it a common expectation that a developer should be spending a good chunk of time in Adobe on asset manipulation?
Additionally does anyone have any process or program suggestions that may make life easier?
I read the AskReddit thread on "What costs less than $100 that changed your life?" (link unavailable since I'm at work) but someone responded "SQL" - jobs just open up that make a ton of money.
I did a cursory search on Indeed and holy moly they were right -- SQL jobs get easily 2x what I make now. I'm pretty good at Excel and that sort of thinking, so I was thinking I'd try taking a class.
Do yall have any recommendations as to a good course to take in SQL, preferably online, preferably free or cheap? I'm willing to pay a bit if it'll mean I can make a lot more, but I'm currently not making a ton, haha.
Any responses welcome, including ideas as to how to break into like, tech-oriented fields as well.
I've been thinking on and off about packaging up a few simple Python utilities I've written to stick up on Github for people to use if they want, but, every time I go to check out how one goes about managing dependencies and all that for a project, I run into a whole wall of options. Does anyone better versed in all of this have any recommendations for me?
I have two computers (a desktop and a laptop) that broke down just before my city entered a lockdown. Being able to assemble and fix my own computer hardware is something I have always wanted to do, and if I knew that I would probably not be using a borrowed Macbook Air right now.
I have no immediate need to provide any maintenance services, nor do I require a primer in electronics or anything too advanced. Just enough to know how to assemble and disassemble a machine, identify and fix the most obvious issues without breaking anything.
I tend to learn better from sequential and structure learning materials, preferably in text/images form. But videos are also welcomed. I know the names of the things and what they are, but I don't really know how to put things together in practice.
Suggestions? :)
I have basic notions of HTML and CSS, but nearly zero JS knowledge. I can perform simple customizations and I know how to follow instructions.
It is not my intention to create anything from scratch (so the platform should have plenty of free themes), nor do I want to become a webdev or webdesigner. This is not a technical project for me, my main concern is the content.
I currently have a blog that uses Wordpress with a purchased theme. It's good enough, but a bit slow to load. Besides, simpler platforms might be easier to understand and manipulate.
This alternative would also need to be FOSS and easy to self-host.
As a plus, it would be awesome if I could manage the blog/website from within Emacs/Org Mode.
Any ideas?
I have a large VirtualBox VM on an external HDD. The HDD fails the S.M.A.R.T. test. The VM still works fine, but any regular attempt to copy the VM files over to a healthy drive fails ... there is clearly already something corrupt in the VM's virtual HDD, although it is not (apparently? yet?) affecting the functionality of the actual VM.
Any suggestions on how to save the VM? Linux Mint Guest OS, Pop_OS (Ubuntu) Host. The VM is nearly 800 GB. Both regular copy and rsync fail.
Thanks,
Eric
PS: (and perhaps I should have led with this, but...) is it okay to ask these kinds of specific, technical, "help me with my tech-stuff" questions here on Tildes?
Update to the update ... moved update info into a comment ... will keep my progress updated in that primary comment.
Danke, y gracias to all
I'm looking for some feedback on a feasible mechanism for structuring a few API endpoints where a purely RFC-spec compliant REST API wouldn't suffice.
I have an endpoint which returns $child entries for a $parent resource, let's call it: /api/parent/:parentId/children. There could be anywhere from a dozen to several hundred children returned from this call. From here, a child entity is related to a single userOrganization, which itself is a pivoting entity on a single user. The relationship between a child and user is not strictly transitive, but can each child only has one userOrganization which only has one user, so it is trivial to reach a user from a child resource.
Given this, the data I need for the particular request involves retrieving all user's for a parent. The obvious, and incorrect solution to the problem is to make the request mentioned above, and then iterate through and make an API request to retrieve each user. This is less than very good as this would obviously be up to several hundred API calls.
There's a few more scalable solutions that could solve this problem, so any input on these ideas is great; but if you have a better proposal that also works, I'm keen to explore that!
user relationships in the call by default.This certainly does solve the problem, but it's also pumping down a load of data I don't necessarily need. This would probably 2x the amount of bytes travelling along the wire, and in 8 out of 10 calls, that extra data isn't needed.
/api/parent/:parentId/users call.Another option that partially solves the issue: I need data from both the child and the user to format this view, so I'd still need to make the initial call I documented earlier. Semantically, it feels a bit odd to have this as a resource because I don't consider a user to be nested under a parent in terms of database topology.
This comes across as the 'least worst' idea objectively, in terms of flexibility and design. Through the addition of the query parameter, you could optionally retrieve the relationship's data. This seems brittle and doesn't scale well to other endpoints where it could be useful though.
expands-style query parameter.Stripe implements the ability to retrieve all related records from an API endpoint by specifying the relations as strings. This is essentially the same as the above answer, but is scaled to all available API endpoints. I love this idea, but implementing it in a secure way seems fraught with disaster. For example, this is a multi-tenancied application, and it would be trivial to request userOrganization.user.organizations.users. This would retrieve all other organisations for the user, and their users! This is because my implementation of expands simply utilises the ORM of my choice to perform a database join, and of course the database has no knowledge about application tenancy!
Now, I do realise this problem could easily be solved by implementing a GraphQL API server, which I have done in the past, but unfortunately time and workload constraints dictate implementing a GraphQL-based solution is infeasible. As much as I like GraphQL, I'm not as proficient in that area as compared to implementing high quality traditional APIs, and the applications I'm working on at the moment are focusing on choosing boring technology, and not using excessive innovation tokens.
Furthermore, I do consider the conceptuals around REST APIs to be more of an aspirational sliding scale, rather than a well defined physical entity, because let's face it, the majority of popular APIs today aren't REST-compliant, even Stripe's isn't, and it's usually both financially healthier and feature-rich to choose a development path that results in a rough product that can be refined later, than aiming for a perfect initial release. All this said, I don't mind proposals or solutions to my problem that are "good enough". As long as they aren't too hacky! :)
I'm interested in C or Go, but i'm open to ideas.
I have plenty of sh scripts i created to integrate my tools and system, so i have some experience and i don't want a scripting language like python.
My first plan is to learn the basics of the language and rewrite some of those scripts.
I think my first pick will be a script that uses ffmpeg to convert my flac files to mp3 or opus. I use sndconv -opus/-mp3 and it checks if there are flac files in the folder (i only have full albums), converts and puts in a folder named "$artist - $album".
My long term goal is to make a cli/tui music player like cmus.
UPDATE: i'm having plenty of success with Go right now. I just wrote a basic version of my music conversion script. It's just converting a music i pass as argument to mp3, but i'll keep working on it and adding functionality just to dip my toes in Go. It seems like a good language and i'm having fun!
Thanks for all the answers!
I'm a beginner in programming, but a veteran in film and literature. I know that ideas come easy. Any normal person can come up with a good idea in a matter of minutes. The main problem is doing it.
Besides, I couldn't care less if someone does that before me. I'd probably benefit from their program, and even offer to collaborate. I have a bunch of other ideas in the oven anyway.
And I'm humble enough to know that such a niche project would never attract the interest of a mega-corporation anyway.
CHORES is a short-term task manager. It's meant to organize nothing more than a few hours or less of your tasks. Month, weak or even your entire day are entirely out of its scope.
First and foremost, this app is for my use. But I'm certain there are other people with conditions similar to mine, especially ones with ADHD. I'm also autistic with a compulsive personality, and won't stop until I tinker with every aspect of an object. Not surprisingly, I'm a Linux, i3wm, Emacs and Neovim user. And they're excruciatingly customized.
What I need is not a full-featured a TODO app like Remember The Milk, Todoist or Org Mode. They're too distracting, I end up just playing with the tools. I need something that allows me to track very short term chores. Thinks like brushing my teeth, taking a shower, eating, walking my dog, washing the dishes and making my bed.
That's what I intend to do.
From the United States National Institute of Mental Health:
Attention-deficit/hyperactivity disorder (ADHD) is a disorder marked by an ongoing pattern of inattention and/or hyperactivity-impulsivity that interferes with functioning or development.
Please refrain from suggesting that the ones who use such tools just need to make an effort instead. That's a cliche most people with ADHD and other mental health issues probably heard many times, and by saying that you may cause distress. If you need more information, please refer to the link posted above.
People with severe ADHD like myself frequently forget what they're doing, and what they should do in the very short term. I'm talking 2, 3 or 5 tasks from now. To give you an idea of how bad it is, right now I have an Emacs Org Mode file with the following tasks:
* Now
** TODO Take Ritalin
** TODO Start chronometer on Ritalin
- Tells me when the effect wears off
** TODO Take a shower
** TODO Take the laptop to the living room
** TODO Wash the dishes
** TODO Study Python
** TODO Post on Tildes
But Emacs and Org Mode do a lot more than that, and this can be very distracting (right now I'm writing this post because creating another file from my now.org file was way too easy, for example).
Considering that I am the main target audience of this program, any space for tinkering is a dangerous avenue for procrastination.
The primary target of this project are people with:
In sum: if you have extreme difficulty focusing, remembering and fulfilling your tasks in the very short term, you may find this program useful.
The majority of people can concentrate and perform their short-term tasks with a reasonable degree of efficiency. If that is your case, you have little to gain by using CHORES.
CHORES is a short-term task manager. It's meant to organize nothing more than a few hours: not your month, weak or even your day.
Started Stopped status clearly marked by character or highlightingOrg Mode and Emacs are wonderful tools, but they're also a perfect playground for procrastinators. It simply does too much. Emacs is like a box of legos, and that's the last thing an ADHD person needs when it comes to tracking short-term tasks.
Taskwarrior suffers from the same issue.
This may seem crazy, but for a severe ADHD person, even todo.txt gives way too many options and features. It is, after, an actual TODO app. I can add 1000 tasks todo.txt. It has an extensive wiki, projects, tags, context tags, special value tags. You might just say: just don't use these options. But that
I like t very much, and, depending on its license, I'll probably use at least some of its code. But t lacks some features CHORES requires, such as:
t last tasks randomly, or at least something that seem random to me)This is a very personal anwer, but here we go:
Hi all,
I'm looking for some advice regarding how to set up a basic CI regression / testing suite. This isn't my full time job, but a side project my group at work wants to spin up to... shall we say, give us a more real time monitoring of functionality and performance regressions coming out of the underlying software stack development (long story).
As none of us are particularly automation experts, I was looking for some advice from my fellow Tilderinos. Please forgive me if any of the below is obvious and/or silly.
A few basic requirements I had in mind:
Can handle different execution environments: essentially different versions of the software stack, both in docker form and (eventually) via lmod or some other module file approach (e.g., TCL), and sensible handling of a node list.
Related to one, supports using the products of builds as execution environments. Ideally we'd like to have a build step compile the stack and install it to a NFS from which we can load it as a module.
Simple to add tests. Again, this isn't our full time job -- we mostly want to add a quick bash script / makefile / source code or the like to the tests when we run into an issue and forgot about it.
Related. We should be able to store the entire thing as a git repo. I have seen this to some extent with Travis, but my experience with Jenkins was... sub-par (is there a history? Changelog? Any way at all of backing up the test config?).
Some sort of post-processing capabilities. At a glance we need to be able to see the top line performance numbers for 20-30 apps over the different build environment. Bonus points if there's a graph showing performance vs build version or the like, but honestly a CSV log file is good enough.
Whatever CI software we get has to be able to run this locally. Lots of these are internal only numbers / codes. FOSS prefered.
A webui for scheduling runs / visualizing results would be nice, but again this could be a bash script and none of us would bat an eye.
Any thoughts would be greatly appreciated. Thanks!
It looks like it was much simple than I thought and someone solved it on Reddit already. I won't delete, just leave the link if someone is interested.
Sometimes I use "whereis" (aliased for "wh", but it doesn't make any difference...) for my own scripts.
I usually copy their paths manually (using tmux) and paste to the command line resulting in something like this:
nvim /home/my_username/my_scripts_folder/my_script
Could I make that into a single command?
Thanks in advance!
I know there are similar products I could buy in the US that would give me this experience, but I'm not in the US and I don't have much money.
In the old days, my father had some kind of machine that was not a proper laptop and not a proper typewriter. It opened instantly to a text editor. As far as I remember, there was no noticeable boot time. It had a keyboard and an entry for a floppy disk. You typed your stuff, saved it to the floppy disk, probably to send via email or to print in another machine. I loved that machine.
I love these little gadgets that do one thing and one thing only. And, as someone with severe ADHD, they're often a necessity. If my Kindle had Youtube I would never read a book. If my PS4 had Emacs I would never play a game. The list goes on, but the principle is this: a lot of things are useful to me precisely because of what they cannot do.
And that is why I wanna recreate my father's crazy computer-typewriter.
Because I know how to use the command line, it really needs to be in total lockdown: I open it up, it shows a very simple text editor (with a few handy features that make it works even more like a typewriter) that I cannot configure, tinker or alter in any way. It's focused on writing (not editing) literature because that's what I need and other kinds of writing require an internet connection.
It would save and back up automatically (like a typewriter) to one or more drives at your choice.
There would need to be a few options because of different screen sizes, the number of screens etc, with an interface to make it easier.
So the idea is an ultra-minimal, kiosk-mode Linux distribution that can either go on a flash drive or be installed on an old laptop. No package management, no internet connection, no access to the command line, no configuration files, no distractions whatsoever. I wanna forget I'm even using Linux. I wanna recreate my father's typewriter/computer that he never let me touch.
How do I do this?
Every tutorial I find is geared to graphical interfaces
I've been using Linux for the past 5 to 10 years. I'm not a developer, but a mid-to-advanced user. I don't really know bash (or any programming language for that matter), but I got a folder with 100 bash scripts I wrote myself. I compile my own Emacs (which I configured from scratch and contains more than 200 crudes functions of my own), Neovim (also configured from scratch) and other programs such as suckless terminal. I'm an i3wm user and currently use MX-Linux. I'm very good at Googling and pattern recognition.
I got a brand new AMD desktop with a Ryzen processor (no dedicated graphics, wifi works fine with a USB adapter). Should I try Gentoo, or maybe I should study more (maybe with something like Linux Journey)in order to get a better experience?
Reasons to install Gentoo:
I've got a smaller desk with two monitor arms -- one with a monitor (left side, different system) and one with a VESA mounted tray for my macbook pro (late 2013 15".)
I'm going to be adding a 1440p monitor from the macbook pro, but I'm short on desk space. Instead of having the laptop on the tray normally, if I lay it lid down with the laptop portion up, the laptop base could sit behind the new monitor with the screen coming out the bottom -- perfect for static applications like VSCode, iTerm2, etc.
Here's a mock up. The thicker outline represents the macbook pro screen.
Can anybody foresee any issues with this configuration?
Hello! After spending many development hours in my past years running on Virtualbox/Vagrant-style setups, I've decided to take the plunge into learning Docker, and after getting a few containers working, I'm now looking to figure out how to deploy this to production. I'm not a DevOps or infrastructure guy, my bread and butter is software, and although I've become significantly better at deploying & provisioning Linux VPS's, I'm still not entirely confident in my ability to deploy & manage such systems at scale and in production. But, I am now close to running my own business, so these requirements are suddenly going from "nice to have" to "critical".
As I mentioned, in the past when I've previously developed applications that have been pushed onto the web, I've tended to develop on my local machine, often with no specific configuration environment. If I did use an environment, it'd often be a Vagrant VM instance. From here, I'd push to GitHub, then from my VPS, pull down the changes, run any deployment scripts (recompile, restart nginx, etc), and I'm done.
I guess what I'm after with Docker is something that's more consistent between dev, testing, & prod, and is also more hands off in the deployment process. Yet, what I'm currently developing still does have differing configuration needs between dev and prod. For example, I'd like to use a hosted DB solution such as DigitalOcean Managed Databases in production, yet I'm totally fine using a Docker container for MySQL for local development. Is something like this possible? Does anyone have any recommendations around how to accomplish this, any do's and dont's, or any catches that are worth mentioning?
How about automating deployment from GitHub to production? I've never touched any CI/CD tools in my life, yet I know it's a hugely important part of the process when dealing with software in production, especially software that has clients dependent on it to function. Does anything specifically work well with Docker? Or GitHub? Ideally I want to be avoiding manual processes where I have to ssh in, and pull down the latest changes, half-remembering the commands I need to write to recompile and run the application again.
{kind=link}
{kind=link}