Audio steganography in supply chain attacks
16
votes
If you want to see just the final result, check out my TiMaSoMo showcase post. This post does minimal amount of showcase of the final project, although it does include some pictures. If you want to see a showcase of the software, the original author has made a great video showcasing it that is worth checking out: YouTube videoBlogpost for those who prefer reading. Instead, this post is more a discussion of my experience developing a device.
The goal of this project was to create a dedicated audio player, to separate that capability from my phone. The main source of audio will be streaming Spotify, not local files. Although unfamiliar with them, I felt that a Raspberry Pi was a good baseline device. For audio, I had an old USB DAC/amp that I wanted to repurpose. Using this DAC/amp would allow for some of my harder to drive headphones to work, as well as just getting cleaner audio. Then, I was planning on just using an eInk touchscreen. The rationale for eInk was so that it would feel different than my phone, and just feel like it was intended for music instead of scrolling. The logic was if I put a regular LCD screen on, it would not differ from a smartphone, and therefore I might as well just connect my DAC to my phone and use that. For software, the plan was to just use either Android or some lightweight linux distro. The initial plan for batteries was to just use rechargeable AA batteries, so that I can easily swap them out. One major reason I wanted to go with the DIY route was for repairability, especially with batteries. If I got an existing Digital Audio Player (DAP) on the market, I knew that the Li-Ion battery would eventually go bad, and existing devices on the market may not be easily repairable.
My hardware approach was to buy one component at a time. That way, if I ran into an issue with the feasibility of the approach, I could pivot without having wasted money on all the components ahead of time. This approach did slow down development as I was frequently waiting on hardware, but was more fiscally responsible. In January I got a Raspberry Pi 3a+, and played around briefly with some different operating systems. The next part that was needed was to source the screen.
The original goal was to try and get a touch eInk screen, roughly 5” for a reasonable price. I spent a few weeks trying different places to try and find one, but could not find one. Since I could not find one I started thinking about pivoting to an LCD screen. With this pivot, I started defining goals of the project more. If I were to just use an LCD touchscreen potentially running Android, what makes it different from using my phone? I spent a few weeks trying to define the goals of the project, and was not able to come up with satisfactory answers if I went with an LCD screen.
In the process of trying to figure out my approach, I stumbled across this YouTube video. I felt like this would be a good starting point. It seemed to solve the issue of it not being another Android device, which was my main problem I was trying to solve. However there were a few parts of the implementation that I did not like:
Luckily, for the clickwheel, someone on the weekly programming project on Tildes pointed out this new clickwheel. Since that seemed to be a reasonable approach I ordered one and also got a small LCD screen from Amazon. Unfortunately, the screen used up all the GPIO pins and had non-existent documentation or drivers. I was unable to get the screen to work, so I returned it and ordered a Waveshare 2” LCD. I was intentional on finding one that could be a regular display without using too many GPIO pins. The Waveshare screen had significantly better documentation, and with a bit of work I was able to get it working. With that solved, I started wiring in the clickwheel, and creating basic code to detect basic inputs, which I then used to modify the original code for the Spotify player to handle my clickwheel (see below for comments on code modification). Once I had the screen and clickwheel, I could also develop the software while waiting for parts. Image showing the early iteration of the device
The last main part I had to solve was batteries. Another helpful comment on the weekly programming thread on Tildes told me about 14500 and 18650 batteries. I sourced a 14500 charger and some 14500 cells from Amazon. I had some issues with the first charger I got, and since they were shipping directly from China, it meant the second one would take another few weeks. Picture of using the 14500 battery. The cells I sourced said they were 2500 mAh. I tried one out, and had playtime of about 30mins, not enough to even listen to a full album on a single charge, which is inadequate. I used a portable battery bank rated at 10000 mAh to set a benchmark, and that lasted significantly longer (I was probably around 50% after about five hours or so of playback). This indicated that the 14500 cell was falsely claiming capacity, which is apparently a common issue on Amazon. It also seemed like 14500s rarely have capacity above 700mAh, so I realized that a 14500 would not work. So I decided to upgrade to an 18650 cell, which I could source the actual battery locally from a reputable vendor, with a capacity of 3400mAh. Since I realized that small hobbyist electronics like this on Amazon were shipping directly from China, I started ordering from AliExpress for the charger, which saved me some money for the same part (and even picked up a spare just in case). Picture of me using the 18650 to listen to music on my balcony during the summer. Since I did not need the extra power of the RPi 3a+, and the battery was taking more space, I ordered a RPi Zero 2w+. I also ordered some micro USB ends to solder to to make internal cabling, as well as a USB-C port to use for charging. By May I had all the hardware parts I needed, and all that was left for hardware was to design a case to 3D print, which is detailed below.
The first thing I tested was installing Raspotify which this project used, and set it up with my DAC. Since that worked, I started to program the clickwheel using GPIO pins. I had never used a RPi before, but found some easy tutorials on programming the buttons of my clickwheel in Python. Once the buttons were programmed, I had to figure out the rotary encoder, but was able to find a Github repo that had a working Python code to process the inputs. I was able to add that, and created a Python class that would handle all the inputs of my clickwheel. Once that was coded, I just had to incorporate that into the code for the Spotify player frontend. I forked the repo, and was greeted with at the top of the main file this comment:
# This code is a mess.
# This is me learning Python as I go.
# This is not how I write code for my day job.”
This was not an encouraging comment to read, as at the start my Python skills were relatively low. I was able to quickly find where the inputs from the clickwheel were being handled. The original code had clickwheel inputs being handled in a separate C program and then communicating to the Spotify frontend via sockets. Since my clickwheel code was handled via a Python class I was able to simplify it, and not require sockets to be used. With that working, I just had to set up all the required steps to get the project working. Unfortunately, the documentation for deployment was extremely lacking. I was able to find a Github issues post that provided instructions so was able to get it all set up. I was able to get to this phase by the end of March.
Once I had it all working, I could start on expanding the software to fit my use case as well as start working on any bugs I encounter. I felt a good starting point in handling this was to start addressing the issue of “this code is a mess.” Cleaning up the code would be a good way to gain familiarity with the code as well as make it easier for me to address any bugs or future enhancements. I started work on creating a class diagram, but it was really tedious to do it from scratch with such a large codebase, so I deserted that plan quickly. I am thinking of creating some sequence diagrams from some features I implemented recently, which would help in general documentation to refer back to in the future. I did find some classes that would make more sense in separate files, so did do that. I also started adding in new features as well. The first was to implement a “hold switch” which turns off the screen and disables the clickwheel input. Before, the screen would be on a 60sec timer to turn off, but I felt that sometimes I would want to have the screen stay on (like if I am just sitting in a chair listening to music). This was a relatively easy feature to implement. One bug that kept on appearing is that the screen would frequently freeze on me, normally about 60sec into a song, but would update once the next song started playing. I spent several weeks tracking down this issue, thinking it was software related, as the screen used to timeout after 60sec. I also thought it might be a configuration of my OS, so did some debugging there as well. Finally, I plugged in my main desktop monitor, and realized when the small 2” screen would freeze, my desktop monitor would not. This lead me down to investigating the driver for my screen. I found an issue with someone having similar issues with the original driver that Waveshare forked. I then realized that there was a setting that the screen would stop updating if less than 5% of the pixels were changing. Once I changed that in the config file, the screen freezing issue stopped. I was able to solve this major issue by late July.
The last major feature I have implemented is to create the ability to add new WiFi networks from the app itself. This was a needed feature if I wanted to bring it anywhere outside of my home, since 3rd Party Spotify apps cannot download music. Luckily, there was a search feature, which gave me a baseline for text input using the clickwheel. I was able to create a basic page that prompts for the input of a SSID and the password, and then adds that to /etc/wpa_supplicant/wpa_supplicant.conf and then restarts the wireless interface. I added this feature into the overall settings page I added, which also included other useful dev options, like doing a git pull for me to avoid having to SSH into the Rpi to do it. The settings page features were a part of my project for TiMaSoMo.
I started work on the case in late May roughly. The plan was that I was going to design the case and have my friend who owns a 3D printer print out my design for me. To continue with the project goal of repairability, I wanted to avoid using glue for the case. Instead, I wanted to use heated inserts to hold all the components. I had not used any 3D modeling or CAD software before, so it was a learning experience. I settled on using FreeCAD, which I was able to learn the basics of what I needed relatively quickly. I started with a basic case design for a prototype, to help plan out how I would lay things out. On my computer screen, having the device be 40mm thick sounded fine, but after receiving the prototype I realized I would need to be aggressive in thinning out the design. However, this protoype in early June was very helpful in getting a better understanding of how I needed to design it. Case prototype pictures.
The first iteration I was able to get down to 27mm, which was a significant improvement. I received this iteration in mid July. However, there were parts that did not fit properly. Most of the mounting holes were not aligned properly. However, the bigger issue was that at 27mm the device would not be thick enough to hold the DAC and screen stacked on top of each other. This iteration still had the DAC keep the original metal housing, so that I could easily remove it and use it as originally intended if I did not want to continue using my audio player. First case iteration pictures.
The second iteration I decided to remove the metal housing of the DAC, which freed up a lot of internal space, with the main limiting factor of thickness being the 18650 battery. So I kept the thickness around 27mm, but had more internal space. Removing the metal case of the DAC was relatively straightforward, except figuring out how to secure it to the print. Luckily, there were two roughly 2.5mm holes in the PCB, that I was able to use to secure it. I also started to do a more complex design, since I was getting more experienced with FreeCAD. I also moved the RPi to the top of the case, so that the two parts of the case could easily separate, with only micro USB connectors being used between the parts in the top and bottom part of the case(Picture of third iteration showing this feature). For anyone who has had to repair electronics that did not fully separate due to ribbon cables (laptops are the worst for this it seems), you understand the quality of life improvement of having the two parts easily separate. I got this iteration of the case in early September, and found a few issues of parts conflicting. However, with the use of a dremel, I was able to modify it to get it to roughly fit (although janky in some parts).In this picture you can see the power switch, which I had to modify to sit outside the case. I wanted to fully assemble it, so that I could start using it and figure out where it needs to improve. The biggest issue aside from conflicting parts was that the top of the case was bulging, so I wanted to add another point of connection to prevent it. This bulge was partly caused by the screen cutout causing a weak point in the top of the case. Second case iteration pictures.
The third iteration was part of my TiMaSoMo project. This was a relatively simple minor tweaks, as well as fix some minor pain points of the previous iteration. I reinforced the top significantly to prevent bending, as well as add a fifth point to secure it. I also added a recess to make accessing the switches for power and hold easier to use (although I think I messed up the hold switch one). Overall, this print worked well, and there is currently no plans for a fourth iteration. Fourth iteration pictures.
Here is all four cases compared side by side
The first lesson I had to learn was how to define project goals. Not being able to source an eInk screen had caused me to pivot, and in doing so I had to reflect on what truly mattered for my project. I knew that DAPs existed, so why build my own rather than buy one? Most DAPs on the market seem to be Android devices where they removed the phone functionality and added in quality audio components. Part of a dedicated audio device was to not have my phone be the everything device that they are, but a second Android device with an LCD screen and better audio components is not the solution. Luckily, I encountered the clickwheel based approach, which did solve that issue (and probably better than an eInk would have). Also, I wanted the device to be easily repairable. Li-Ion batteries go bad, which was another major concern for me with the current options of DAPs. Repairability was something that mattered to me, but I had to embrace what that meant for the form factor. If I went with a non-descript Li-Ion pillow battery, I could probably significantly reduce the size. Understanding that I wanted to avoid just being another Android device and have repairability and replaceable parts as the defining features were useful to keep in mind. That approach did result in compromise though, primarily in physical size at the end.
The second big thing I learned was just the process of sourcing parts for a project like this. The closest project to this that I have done in the past is create a DIY cable tester. That simply just involved some switches, resistors, LEDs, and some AA batteries that I could all source locally. So having to buy more complex electronics where the documentation mattered was a learning curve for me. Luckily, early on I was ordering from Amazon, where returns were relatively easy. The problem with Amazon though was false advertising for batteries and some components were shipping directly from China. So, switching to AliExpress saved me money without adding any additional in shipping.
Learning 3D modelling and getting stuff 3D printed was also a huge learning curve for me. I am glad that I got a very rough prototype printed early on in the process. In designing the prototype, I just was not concerned about saving space. However, once the prototype was printed and off my screen and into my hand, I realized how aggressive I needed to be in compacting things. The other thing with using FreeCAD is I learned too late in the process about part hierarchies, and I still do not fully understand them. Not using part hierarchies properly led me to have to do a redesign on each iteration, as moving mounting holes over a few mm would shift every part added after it. Luckily, my designs were relatively simple, but having hierarchies handled properly would have helped me iterate quicker. On top of getting prototypes in hand quickly, using imperfect prints and just adjusting the parts that didn’t work with with a dremel was useful. If I didn’t do that with the second iteration, I would not have dealt with the issue that the top of the case would bend out over time. Spending time using the imperfect device helped me figure out the issues to make the next iteration better.
The first goal I will add in future expansion is to add better documentation and create a better development workflow. Right now, my process includes pushing any changes I do (luckily I am using Github branches now), then pulling the updated repo and starting it on my Pi. However, I never test if it compiles properly before pushing, so I end up sometimes doing five pushes in ten minutes, playing whackamole with compilation errors. Being able to run a dev version on my desktop with keyboard emulation for inputs would be beneficial.
Another big issue that I want to solve is that I need to clean up the audio on lower resistance headphones like my IEMs. There appears to be some electrical noise, that only sensitive devices like IEMs detect. The solution I am currently considering is to add in a capacitor on the voltage rail between the Pi and the DAC to hopefully get cleaner power.
Another issue is that I currently have no indicator of battery life. Since it is an 18650 Li-Ion battery, I should be able to just detect the gradual decrease in voltage, and calculate battery percentage. However, GPIO pins appear to be unable to do that natively, so I may have to add in a small controller board to do it. I have not looked too much into this.
There are a few UI/UX decisions that do not match my preferred way of listening to music. So over time I plan on gradually tweaking the UI/UX to match what I want it to be. A prime example of this would be that when I select an artist, I want it to present a list of their albums, instead of playing their most popular songs.
I want to be able to use Spotify Lossless, since that has rolled out near the end of this project. Unfortunately, it seems that currently it will not be supported. Seems like Librespot (which is the basis for Raspotify) does not currently have a solution that does not involve working around Spotify’s DRM.
Overall, I am really glad I took on this project. It took a long time for me to get it to a finished state. However, the experience has been really fun, and I have learned some new skills. Also, having a dedicated device that all it does is stream Spotify is really nice. I always found myself whenever I was listening to music ending up scrolling on my phone for a bit more stimulation, and then realized I have not been paying attention for the past couple of songs. Having a device where all I do is just listen to music and leave my phone behind has been nice. Also, modifying the code to fit my preferred use case has been nice. There are points where I realize I do not like how something is laid out, but then I have agency to change the layout. Here are some pictures of the final device.
If you want to build the device yourself, I will warn you that it has some rough edges. Also, the DAC/amp is discontinued, so sourcing that to fit inside the case would be tricky. However, my Github repo has all hardware listed, the code needed, and easy to follow software deployment instructions.
Gonna try and put this into words.
I am pretty familiar with bash and python. used both quite a bit and feel more or less comfortable with them.
My issue is I often do a thing where if I want to accomplish a task that is maybe a bit complex, I feel like I have to wind up making a script, let's call it hello_word.sh but then I also make a script called .hello_world.py
and basically what I do is almost the first line of the bash script, I call the python script like ./hello_world.py $@ and take advtange of the argparse library in python to determine what the user wants to do amongst other tasks that are easier to do in python like for loops and etc.
I try to do the meat of the logic in the python scripts before I write to an .env file from it and then in the bash script, I will do
set -o allexport
source "${DIR}"/"${ENV_FILE}"
set +o allexport
and then use the variable from that env file to do the rest of the logic in bash.
why do I do anything in bash?
cause I very much prefer being able to see a terminal command being executed in real-time and see what it does and be able to Ctrl+c if I see the command go awry.
in python, you can run a command with subprocess or other similar system libraries but you can't get the output in real-time or terminate a command preemptively and I really hate that. you have to wait for the command to end to see what happened.
But I feel like there is something obvious I am missing (like maybe bash has an argparse library I don't know about and there is some way to inject the concept of types into it) or if there is another language entirely that fits my needs?
Current Library: built in sqlite
Current db: sqlite (but will have access to Snowflake soon for option 1 below)
Wondering if anyone here has some advise or a good place to learn about dealing with databases with Python. I know SQL fairly well for pulling data and simple updates, but running into potential performance issues the way I've been doing it. Here are 2 examples.
Dealing with Pandas dataframes. I'm doing some reconciliation between a couple of different datasources. I do not have a primary key to work with. I have some very specific matching criteria to determine a match (5 columns specifically - customer, date, contract, product, quantity). The matching process is all built within Python. Is there a good way to do the database commits with updates/inserts en masse vs. line by line? I've looked into upsert (or inserts with clause to update with existing data), but pretty much all examples I've seen rely on primary keys (which I don't have since the data has 5 columns I'm matching on).
Dealing with JSON files which have multiple layers of related data. My database is built in such a way that I have a table for header information, line level detail, then third level with specific references assigned to the line level detail. As with a lot of transactional type databases there can be multiple references per line, multiple lines per header. I'm currently looping through the JSON file starting with the header information to create the primary key, then going to the line level detail to create a primary key for the line, but also include the foreign key for the header and also with the reference data. Before inserting I'm doing a lookup to see if the data already exists and then updating if it does or inserting a new record if it doesn't. This works fine, but is slow taking several seconds for maybe 100 inserts in total. While not a big deal since it's for a low volume of sales. I'd rather learn best practice and do this properly with commits/transactions vs inserting an updating each record individually within the ability to rollback should an error occur.
I am looking for an effective roadmap to become a python backend developer. I am from a non-CS background. I can buy a couple of courses on udemy, if the need arises. TIA!
My project involves reading text from a bunch of PDF form files for which I'm using PyPDF2 open source library. There is no issue in getting the text data as follows:
reader = PdfReader("data/test.pdf")
cnt = len(reader.pages)
print("reading pdf (%d pages)" % cnt)
page = reader.pages[cnt-1]
lines = page.extract_text().splitlines()
print("%d lines extracted..." % len(lines))
However, this text doesn't contain the checked statuses of the radio and checkboxes. I just get normal text (like "Yes No" for example) instead of these values.
I also tried the reader.get_fields() and reader.get_form_text_fields() methods as described in their documentation but they return empty values. I also tried reading it through annotations but no "/Annots" found on the page. When I open the PDF in a notepad++ to see its meta data, this is what I get:
%PDF-1.4
%²³´µ
%Generated by ExpertPdf v9.2.2
It appears to me that these checkboxes aren't usual form fields used in PDF but appear similar to HTML elements. Is there any way to extract these fields using python?
How the heck do these work? I've cobbled together the script below for my bot (using Limnoria) to return the F1 standings in a line. Right now it returns the first value perfectly, but I can't figure out the loop to get the other drivers at all.
import supybot.utils as utils
from supybot.commands import *
import supybot.plugins as plugins
import supybot.ircutils as ircutils
import supybot.callbacks as callbacks
import supybot.ircmsgs as ircmsgs
import requests
import os
import collections
import json
try:
from supybot.i18n import PluginInternationalization
_ = PluginInternationalization("F1")
except ImportError:
_ = lambda x: x
class F1(callbacks.Plugin):
"""Uses API to retrieve information"""
threaded = True
def f1(self, irc, msg, args):
"""
F1 Standings
"""
channel = msg.args[0]
data = requests.get("https://ergast.com/api/f1/2022/driverStandings.json")
data = json.loads(data.content)["MRData"]["StandingsTable"]["StandingsLists"][0]["DriverStandings"][0]
name = data["Driver"]["code"]
position = data["positionText"].zfill(2)
points = data["points"]
output = ", ".join(['\x0306\x02' + name + '\x0303' + " [" + position + ", "+ points + "]"])
irc.reply(output)
result = wrap(f1)
Class = F1
The output should be
VER [1, 125], LEC [2, 116], PER [3, 110], RUS [4, 84], SAI [5, 83], HAM [6, 50], NOR [7, 48], BOT [8, 40], OCO [9, 30], MAG [10, 15], RIC [11, 11], TSU [12, 11], ALO [13, 10], GAS [14, 6], VET [15, 5], ALB [16, 3], STR [17, 2], ZHO [18, 1], MSC [19, 0], HUL [20, 0], LAT [21, 0]
...but it only returns VER [1, 125]
I'm in that state where I can read the stuff, but when I put it together, it doesn't always work.
# this accepts @champ or @constructor with an optional year
# and also @gp with an optional race number for the current season
import supybot.utils as utils
from supybot.commands import *
import supybot.plugins as plugins
import supybot.ircutils as ircutils
import supybot.callbacks as callbacks
import supybot.ircmsgs as ircmsgs
import requests
import os
import collections
import json
try:
from supybot.i18n import PluginInternationalization
_ = PluginInternationalization("F1")
except ImportError:
_ = lambda x: x
class F1(callbacks.Plugin):
"""Uses API to retrieve information"""
threaded = True
def champ(self, irc, msg, args, year):
"""<year>
Call standings by year
F1 Standings
"""
data = requests.get("https://ergast.com/api/f1/current/driverStandings.json")
if year:
data = requests.get(
"https://ergast.com/api/f1/%s/driverStandings.json" % (year)
)
driver_standings = json.loads(data.content)["MRData"]["StandingsTable"][
"StandingsLists"
][0]["DriverStandings"]
string_segments = []
for driver in driver_standings:
name = driver["Driver"]["code"]
position = driver["positionText"]
points = driver["points"]
string_segments.append(f"\x035{name}\x0F {points}")
irc.reply(", ".join(string_segments))
champ = wrap(champ, [optional("int")])
def gp(self, irc, msg, args, race):
"""<year>
Call standings by year
F1 Standings
"""
data = requests.get("https://ergast.com/api/f1/current/last/results.json")
if race:
data = requests.get(
"https://ergast.com/api/f1/current/%s/results.json" % (race)
)
driver_result = json.loads(data.content)["MRData"]["RaceTable"]["Races"][0][
"Results"
]
string_segments = []
for driver in driver_result:
name = driver["Driver"]["code"]
position = driver["positionText"]
points = driver["points"]
string_segments.append(f"{position} \x035{name}\x0F {points}")
irc.reply(", ".join(string_segments))
gp = wrap(gp, [optional("int")])
def constructor(self, irc, msg, args, year):
"""<year>
Call standings by year
F1 Standings
"""
data = requests.get(
"https://ergast.com/api/f1/current/constructorStandings.json"
)
if year:
data = requests.get(
"https://ergast.com/api/f1/current/constructorStandings.json" % (year)
)
driver_result = json.loads(data.content)["MRData"]["StandingsTable"][
"StandingsLists"
][0]["ConstructorStandings"]
string_segments = []
for driver in driver_result:
name = driver["Constructor"]["name"]
position = driver["positionText"]
points = driver["points"]
string_segments.append(f"{position} \x035{name}\x0F {points}")
irc.reply(", ".join(string_segments))
constructor = wrap(constructor, [optional("int")])
Class = F1
Hi all. I am asking this open-ended question (bottom of this post) because I am considering making contributions to an open-source project that would directly benefit me and other users.
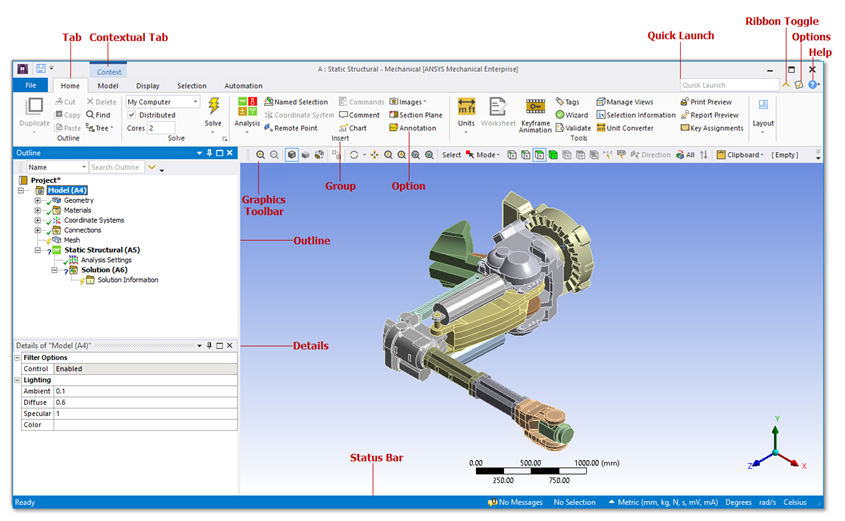
I have worked with an engineering simulation software called Ansys MAPDL basically everyday for the last 4 years, in both an academic and a professional capacity. It's not necessarily relevant whether you are familiar to that program to participate in this discussion. The relevant thing is that the GUI for MAPDL is written in Tcl/Tk and I don’t imagine it is going to be modernized (because of more modern, but distinctly different, replacements). This is a screenshot of the GUI for reference.
The power of the program is not its GUI, but the scripting language that can be run to setup and solve simulations. The program name is really the scripting language name, Ansys Parametric Design Language (APDL). It's somewhat like Matlab. The program also offers an enormous amount of control when compared to the more modern GUI that's been released, since the modern GUI holds a totally different philosophy.
The older GUI is really helpful in certain circumstances because it will spit out a file containing commands that were used in the session. This is a great demonstration of how to run a command or use a setting/config command, but a lot of newer features are buried in the documentation and aren't available in the older GUI.
I know the MAPDL language very intimately, but my experience beyond it is limited to some Perl scripting, and a bit of Python exposure.
Recently, Ansys started supporting an open-source Python project called PyAnsys. MAPDL is otherwise fully closed source, and this is really the only public-facing API. PyAnsys has basically converted a lot of MAPDL script commands to a pythonic format, hence Python can now be used to interact with MAPDL. This is great for several reasons, but is limited regarding interactivity. Interacting with MAPDL via Python is basically happening in a fancy console via Jupyter notebook or IDE like Spyder. Certain commands will bring up Python-based graphics displays of solid models and results plots, but there isn't a dedicated GUI open all the time.
My question is whether it is feasible to write a frontend GUI to a bunch of python commands. If you were going to do it, how would you do it? What might you write it with? Would you even do it? Is this a stupid endeavor?
{kind=link}